Instead of giving a model a fixed retrieval tool, train it to write and execute Python search code over a corpus. The model generates loops, conditionals, string operations — whatever strategy it thinks will find the answer. This outperforms standard single-query RAG and fixed tool-use formats.
How It Works
A two-stage training pipeline on Qwen3-4B (4 billion parameters):
- Supervised fine-tuning on expert search trajectories — teaching the model what good search code looks like
- Reinforcement learning (GRPO) with a judge-model reward signal — letting the model discover its own strategies
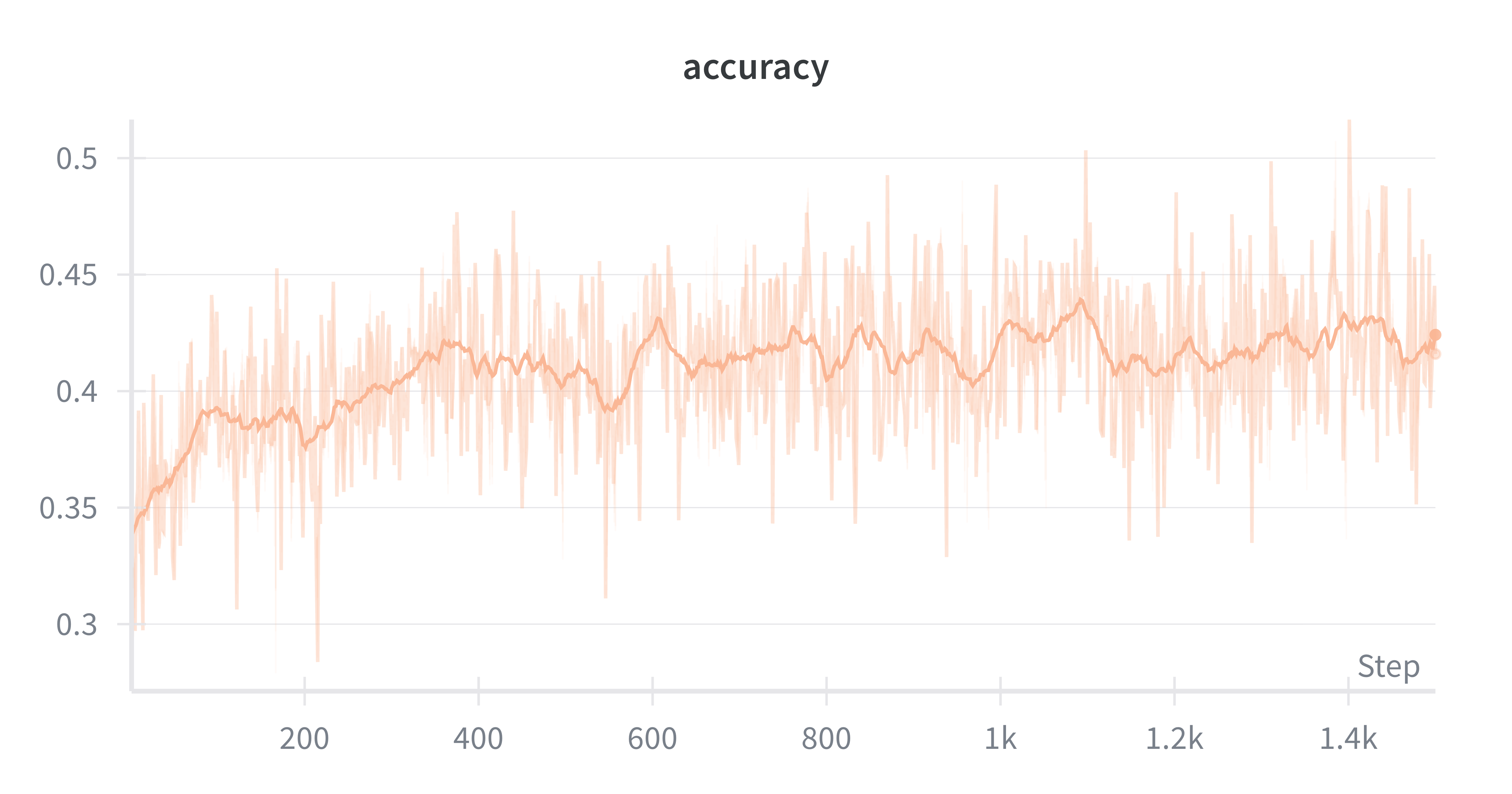
SFT alone improved significantly over the untrained baseline. RL added another 14.5 percentage points on top.
Inference Optimization
Training a 4B model with RL on a single 24GB GPU required careful optimization. Used vLLM for batched rollout generation and KV cache utilization, cutting training time from 50+ hours to ~23 hours.
Results
3.7x improvement over the untrained baseline on agentic retrieval over a Wikipedia corpus.